Designed Finance Research Management System for Aker Solutions
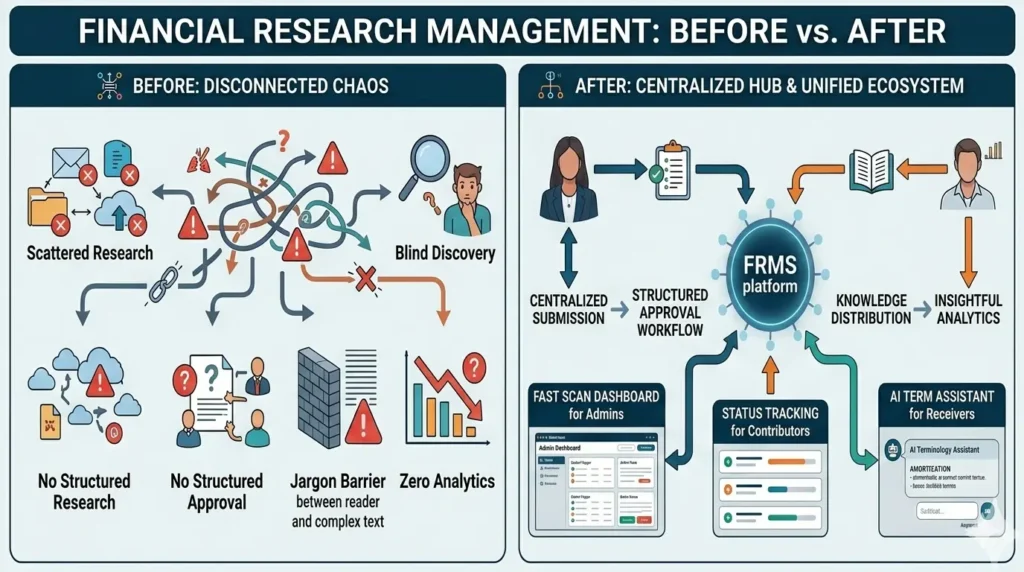
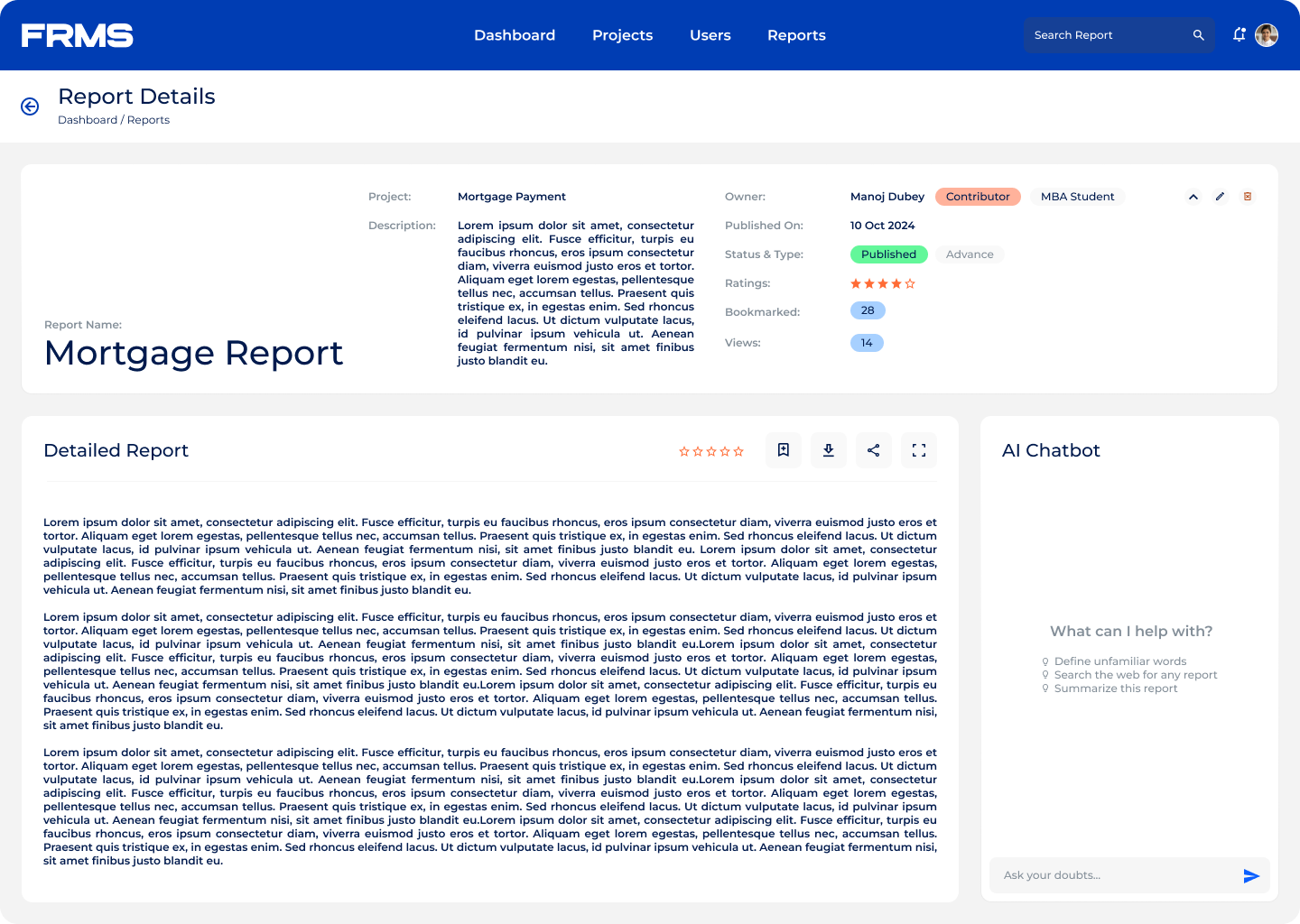
Aker Solutions needed a way to manage financial research internally. Papers were being shared over email, stored on personal drives, and reviewed informally. There was no reliable way to know if a paper had been approved, who had reviewed it, or whether the right people were even finding it.
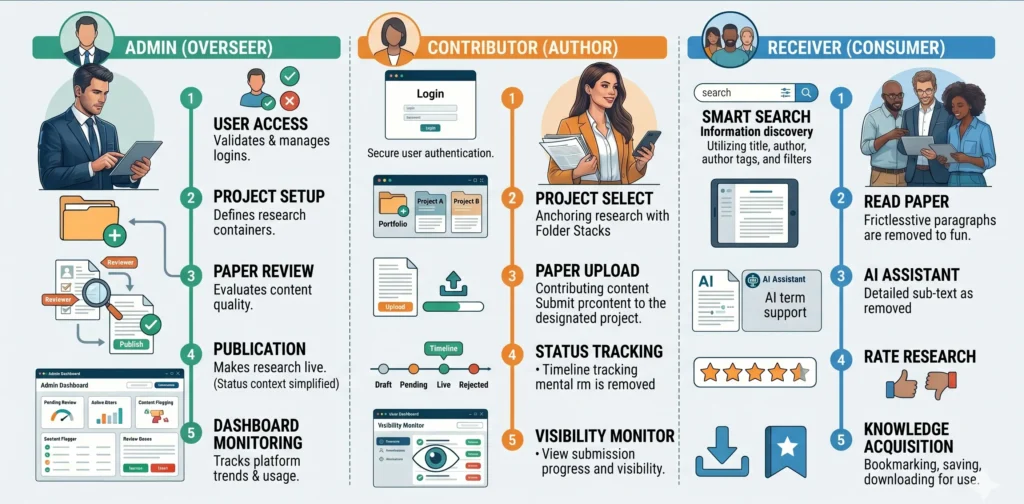
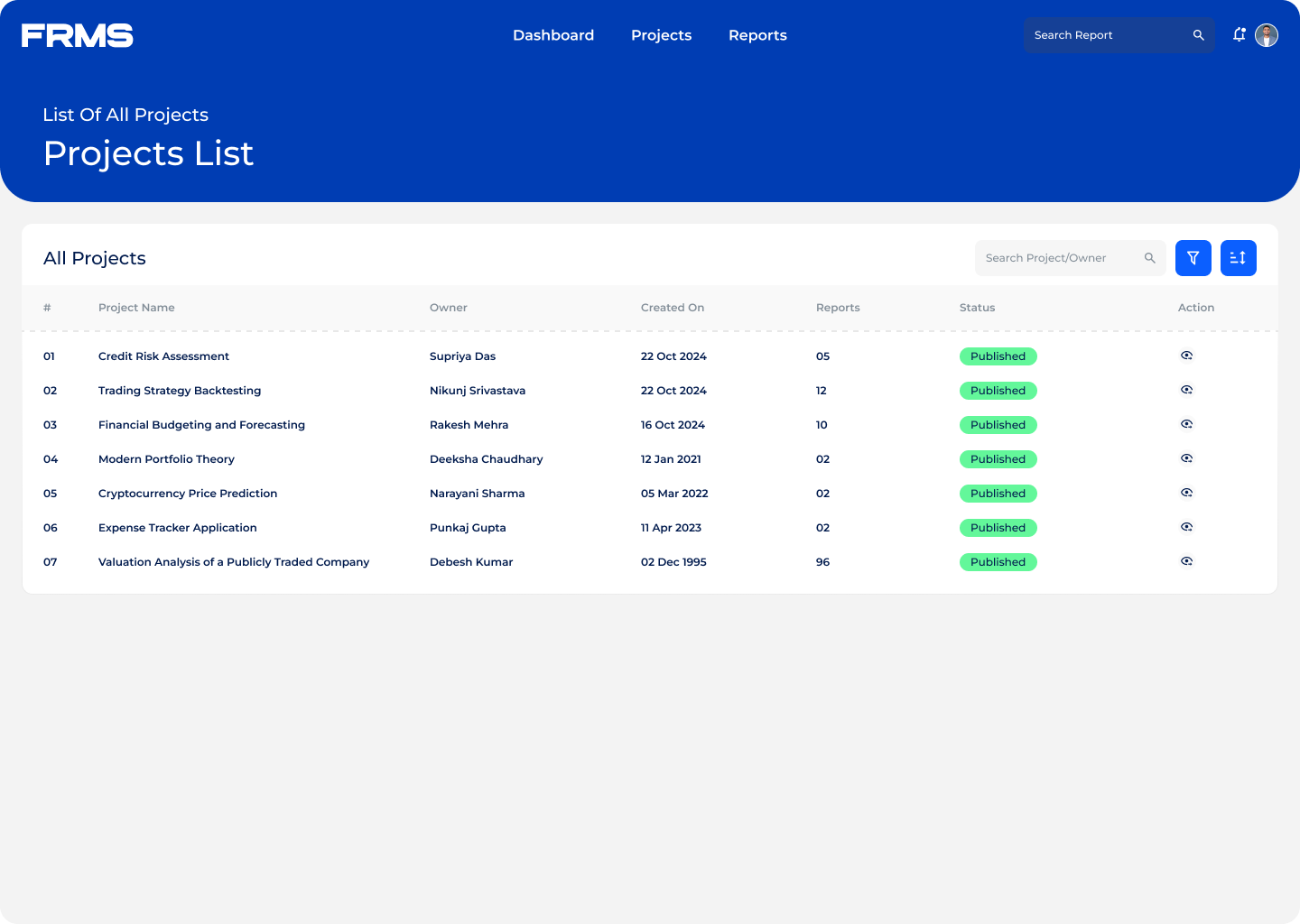
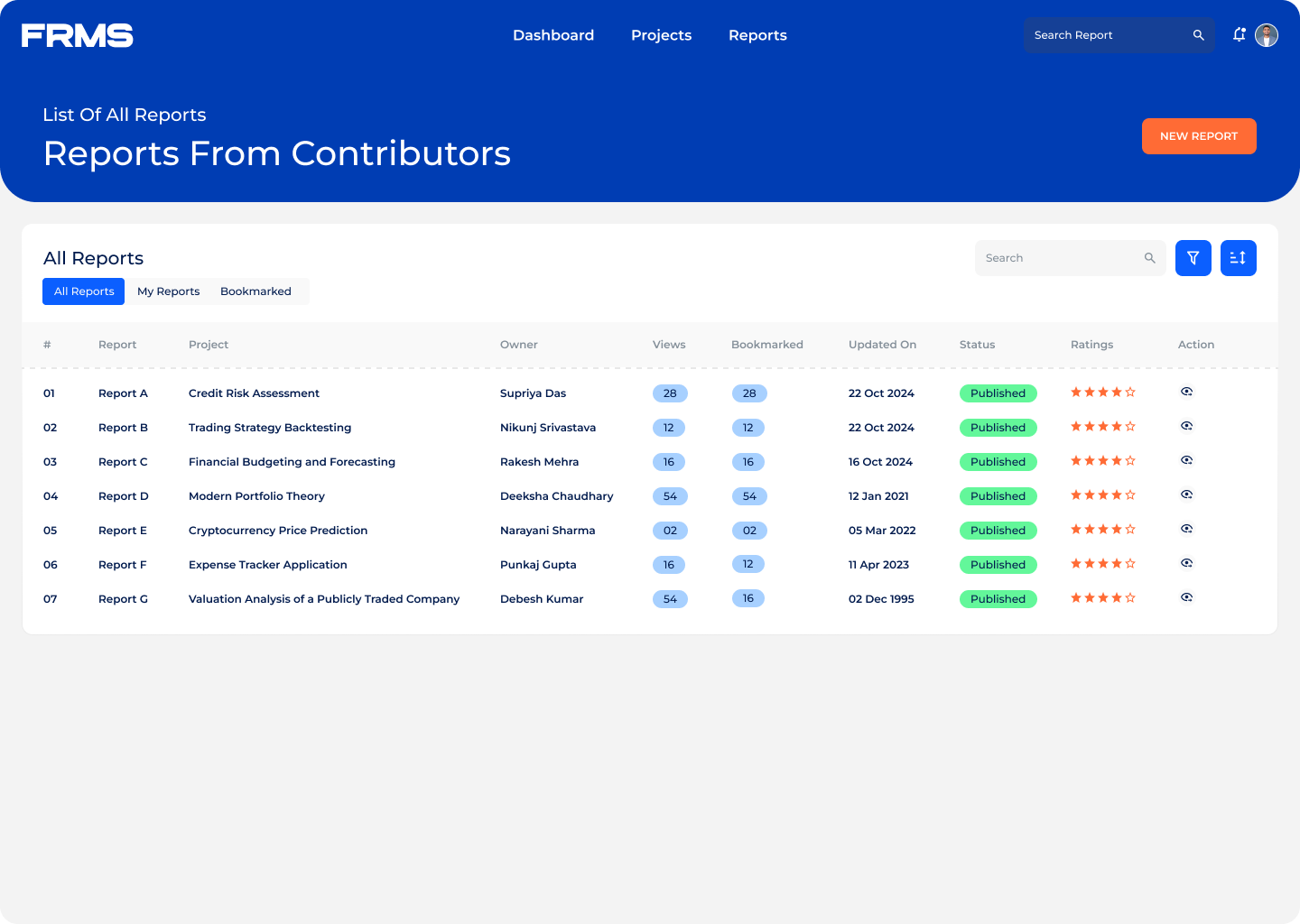
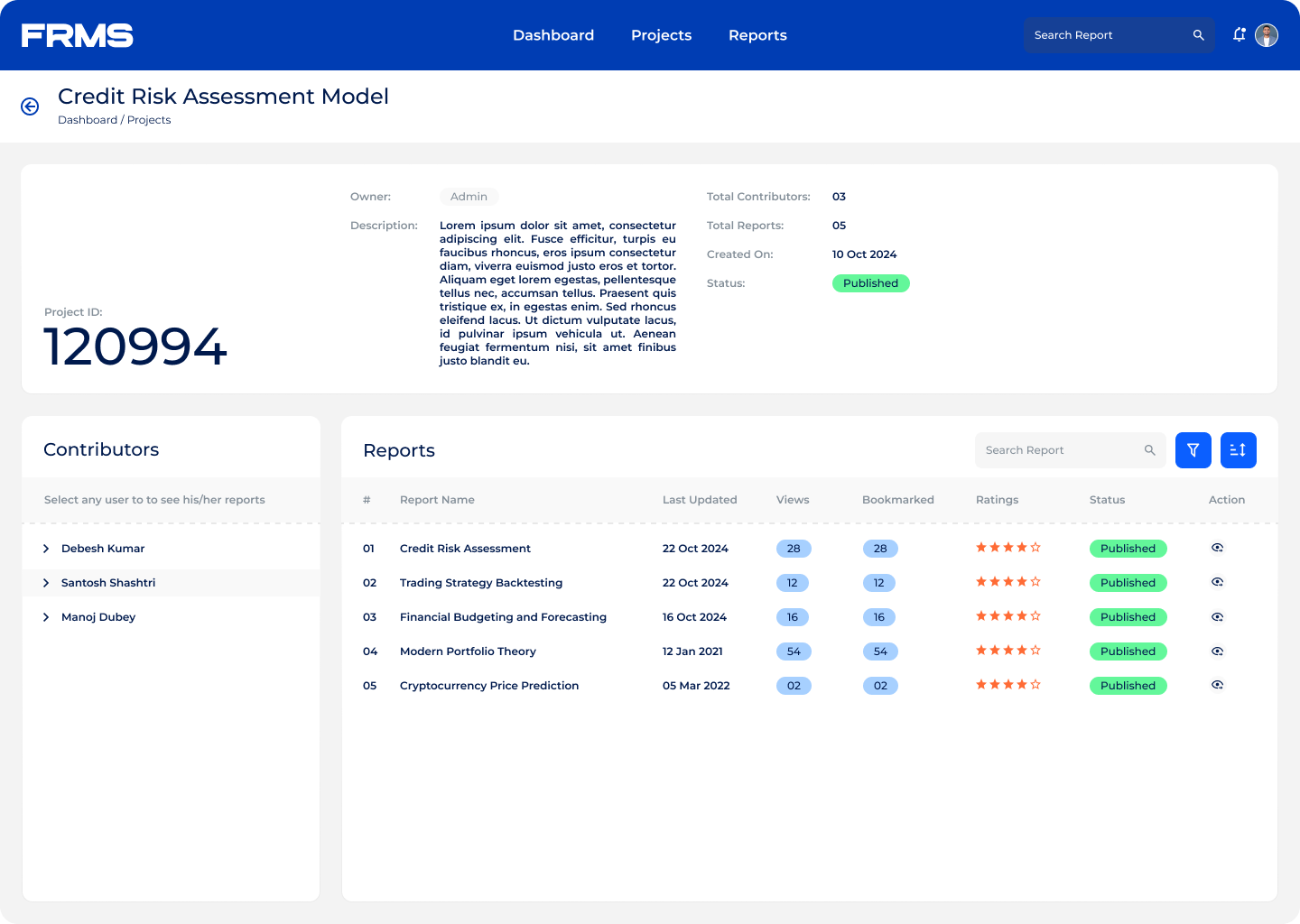
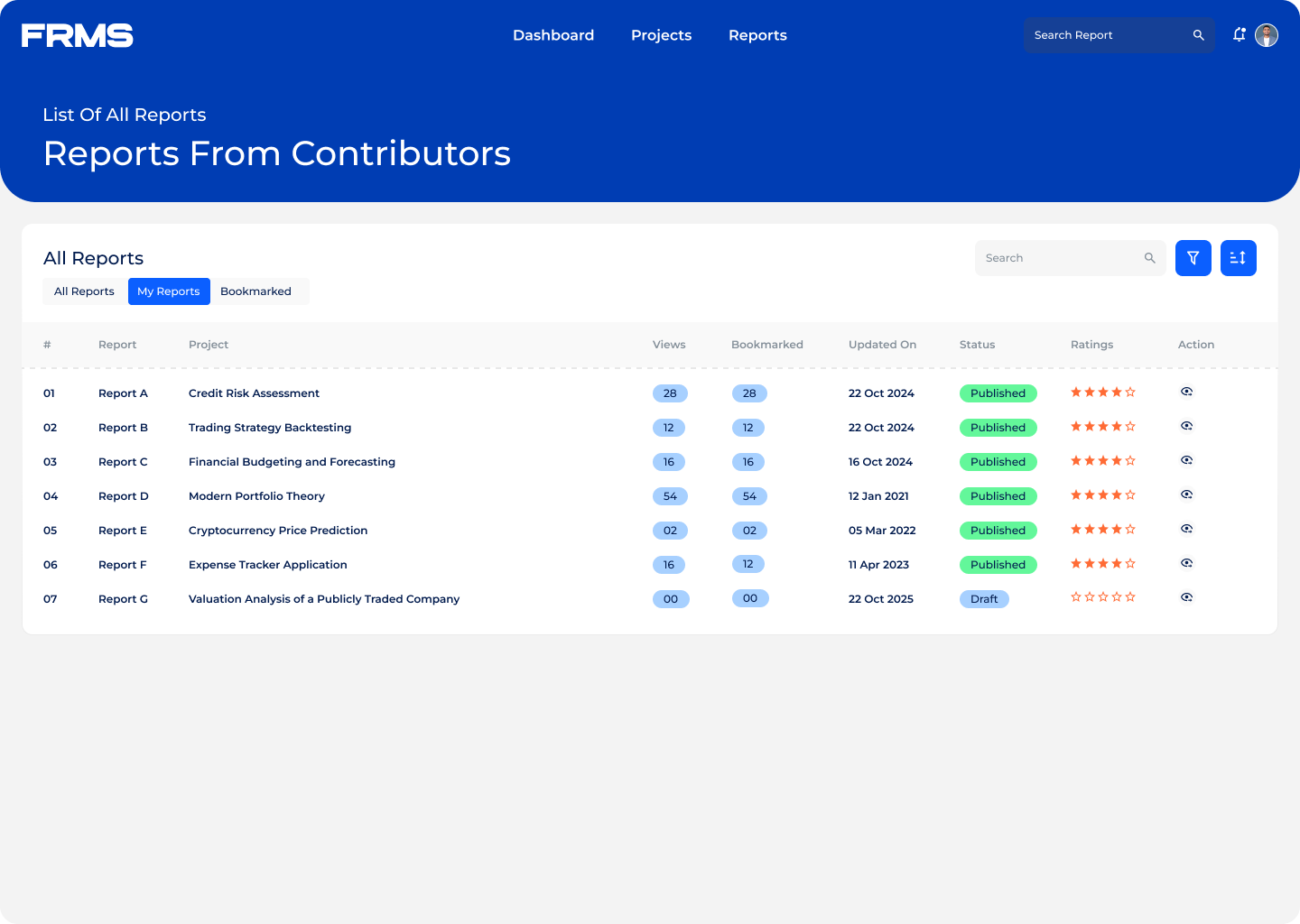
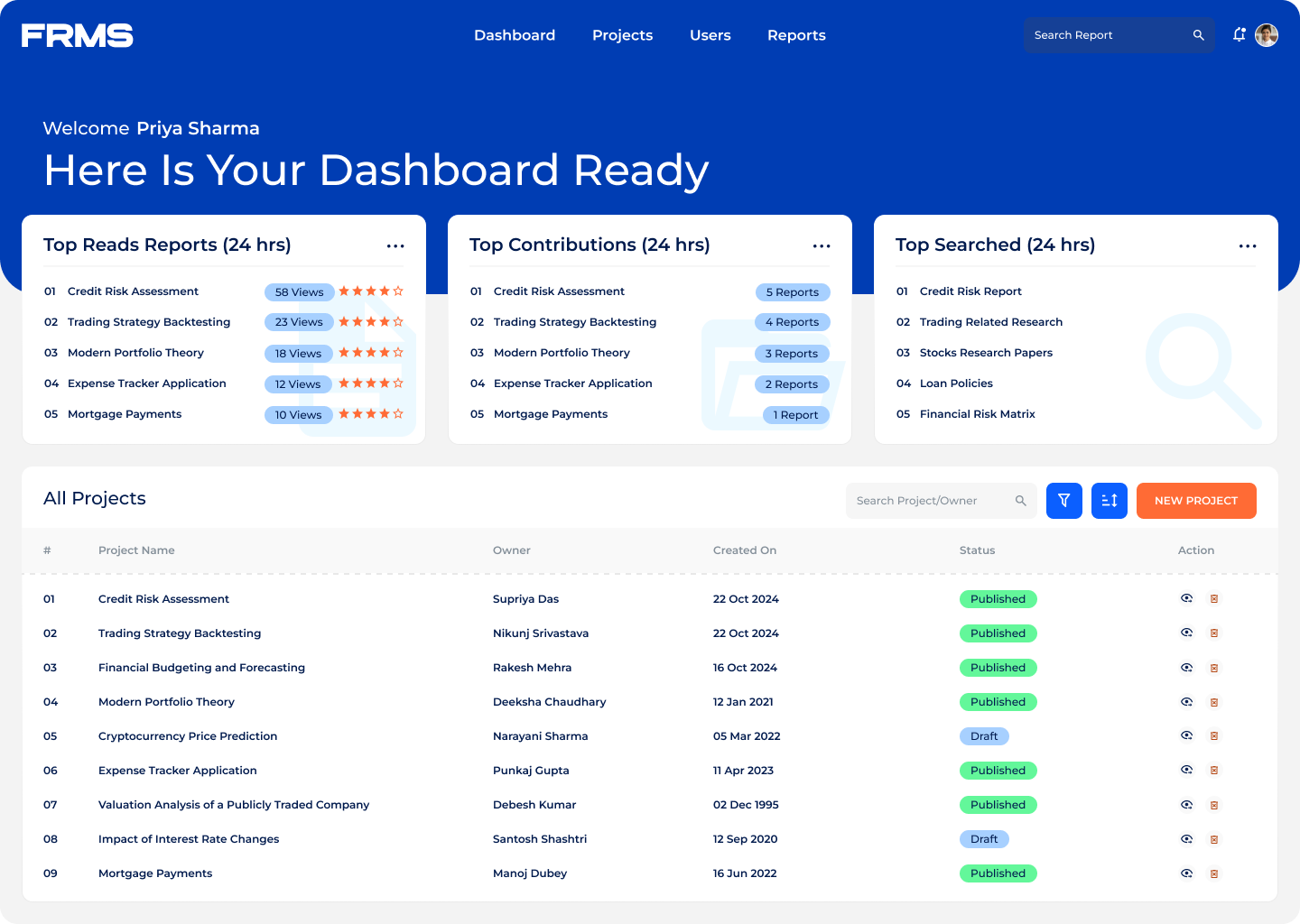
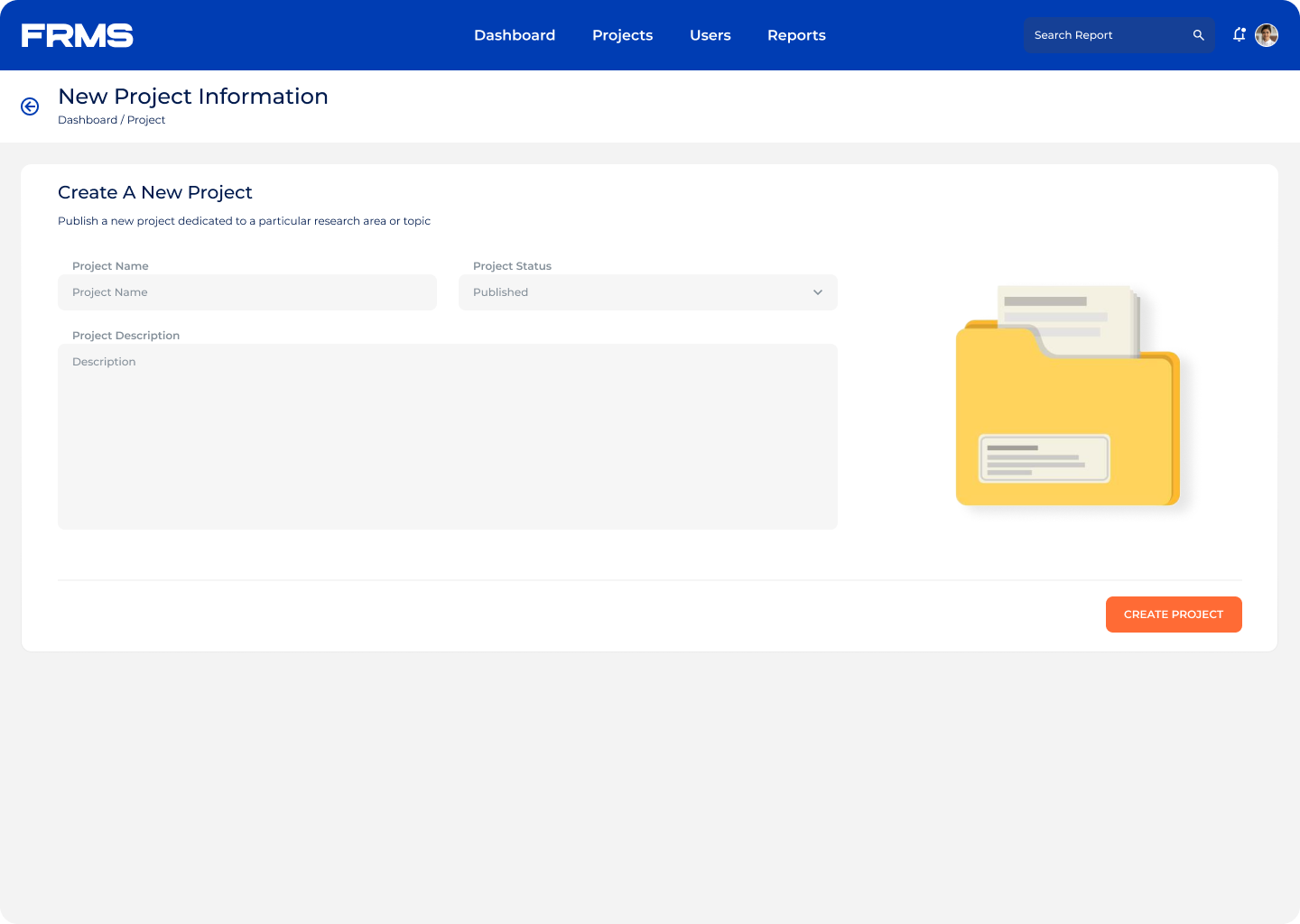
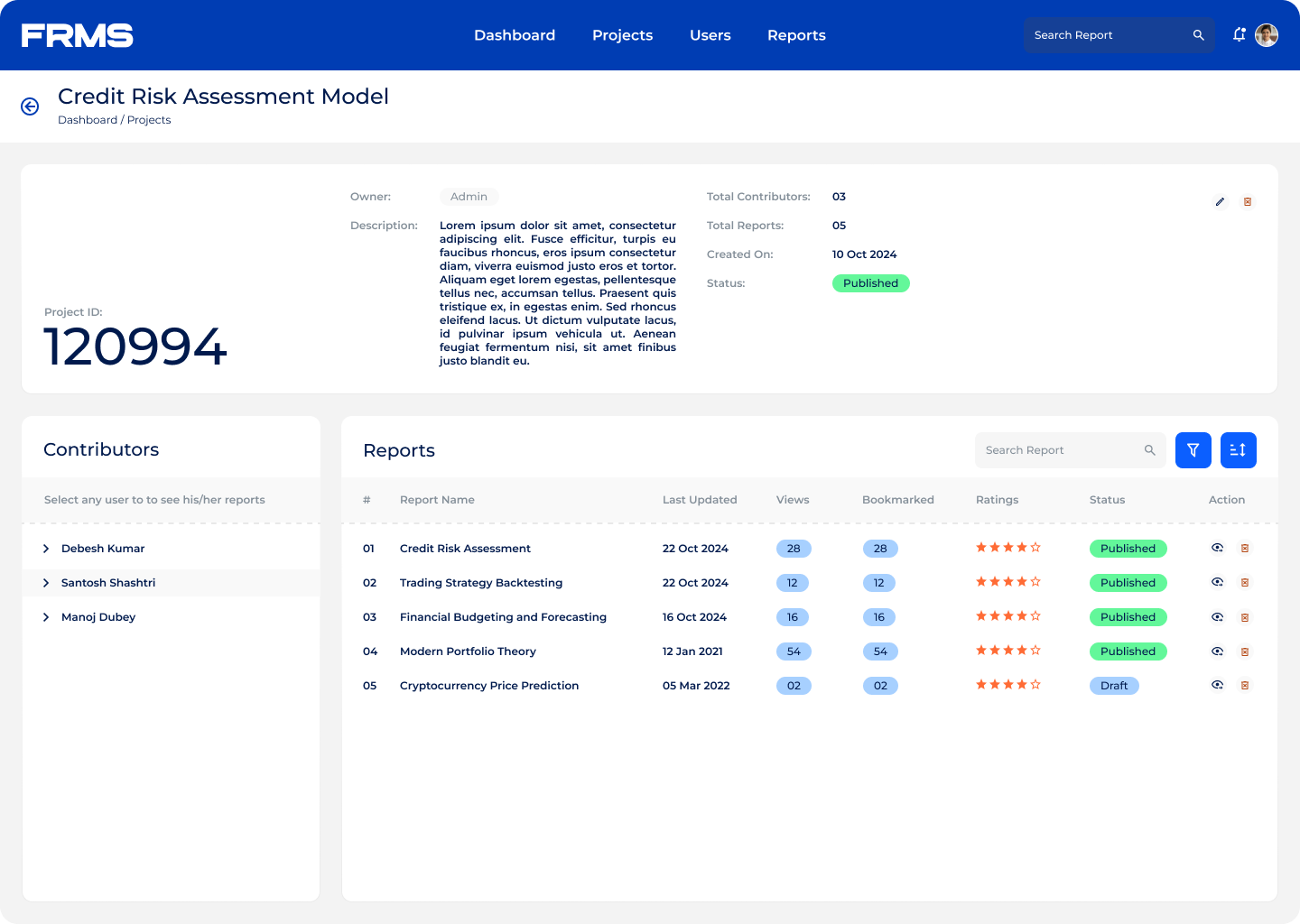
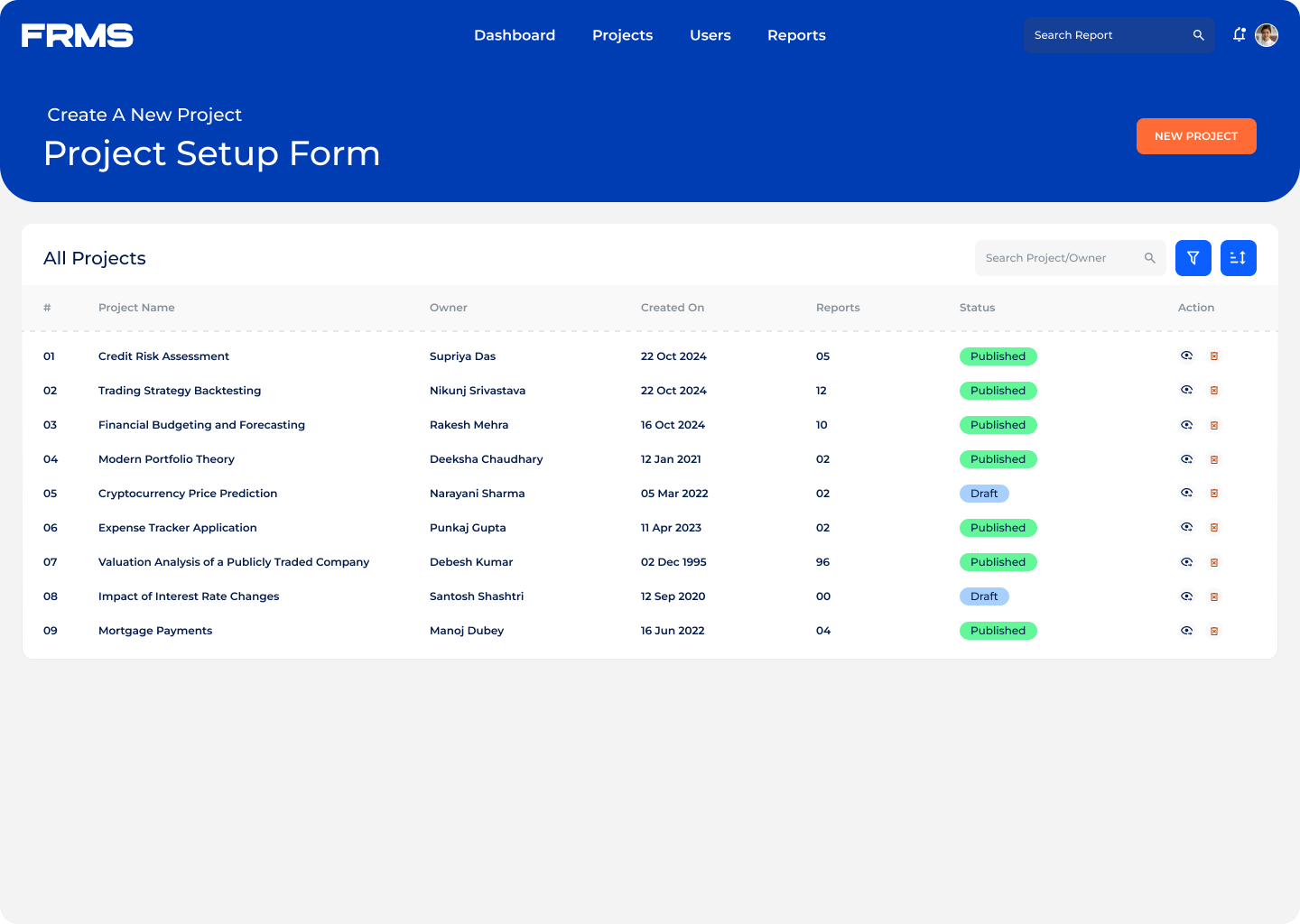
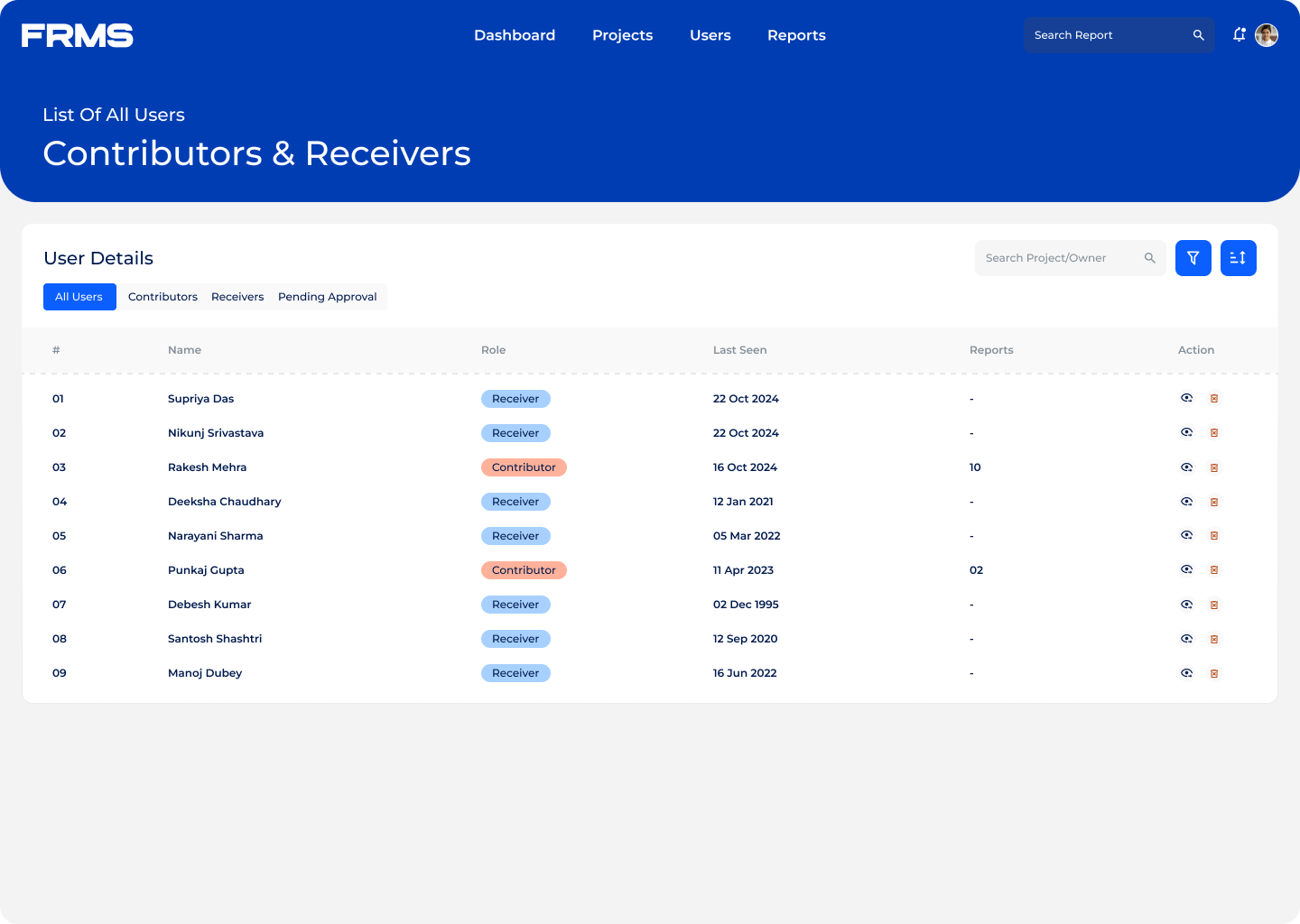
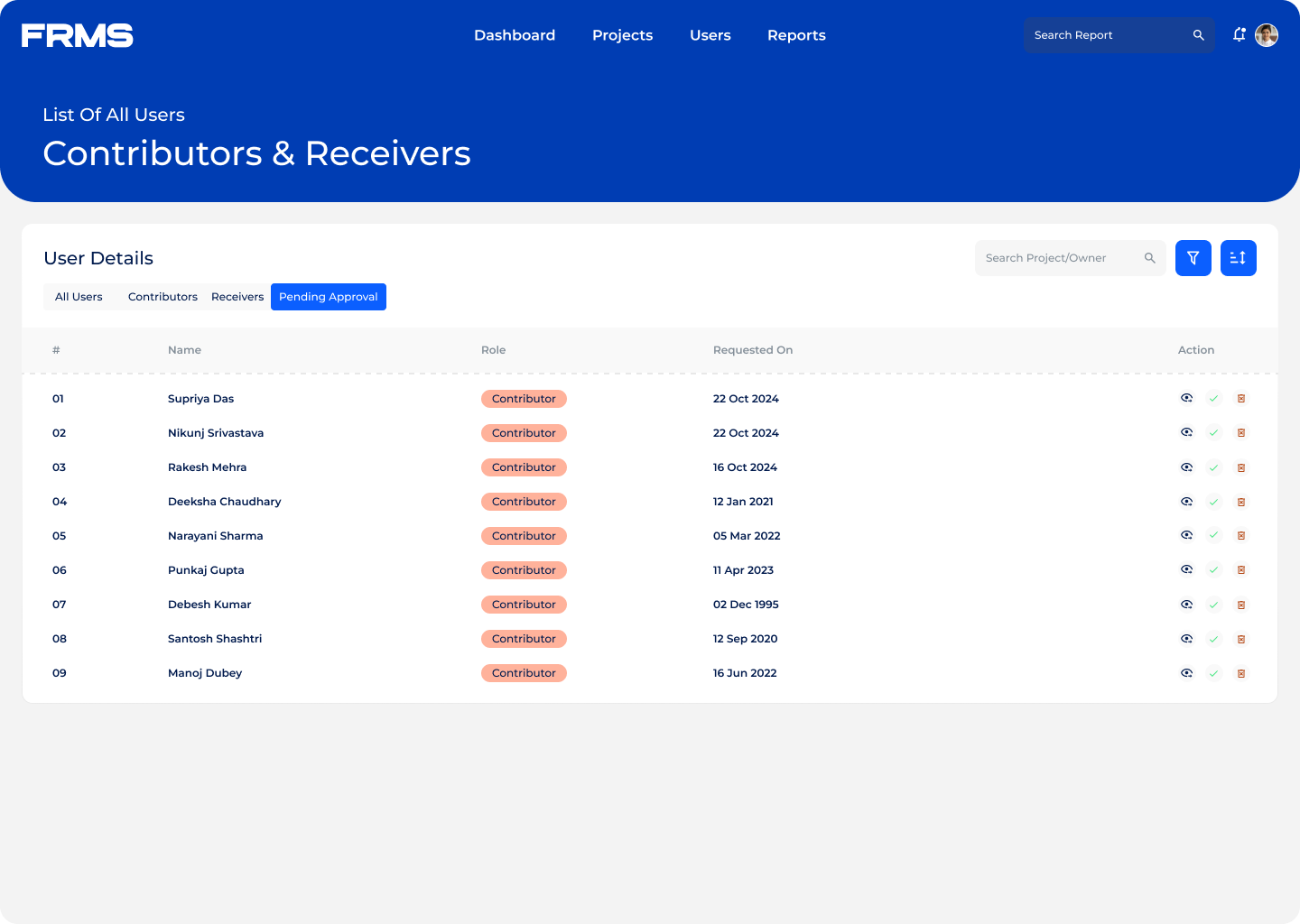
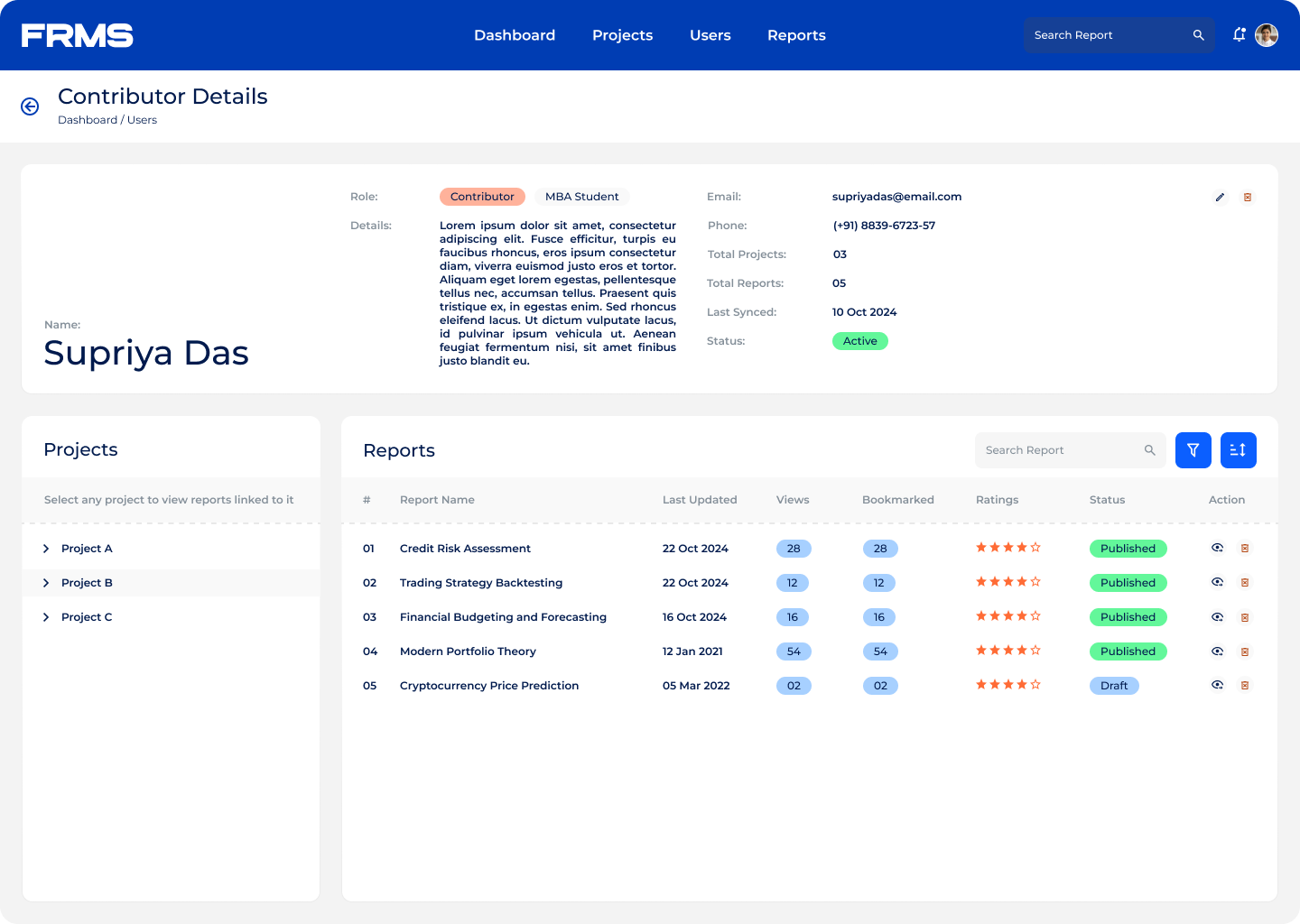
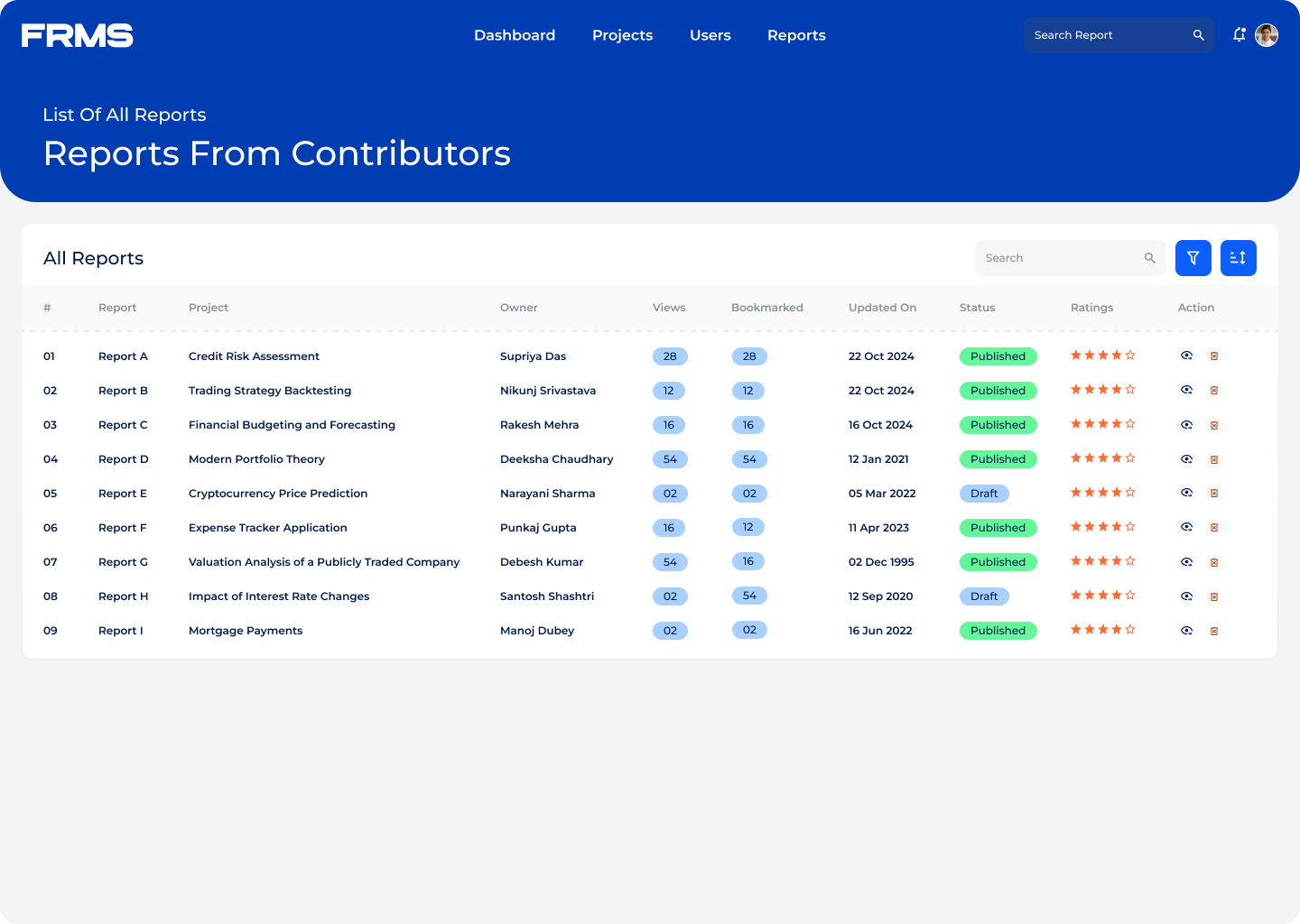
The ask: design a centralised platform for research submission, review, approval, and discovery, and used simultaneously by three completely different types of users.
Core platform goals:
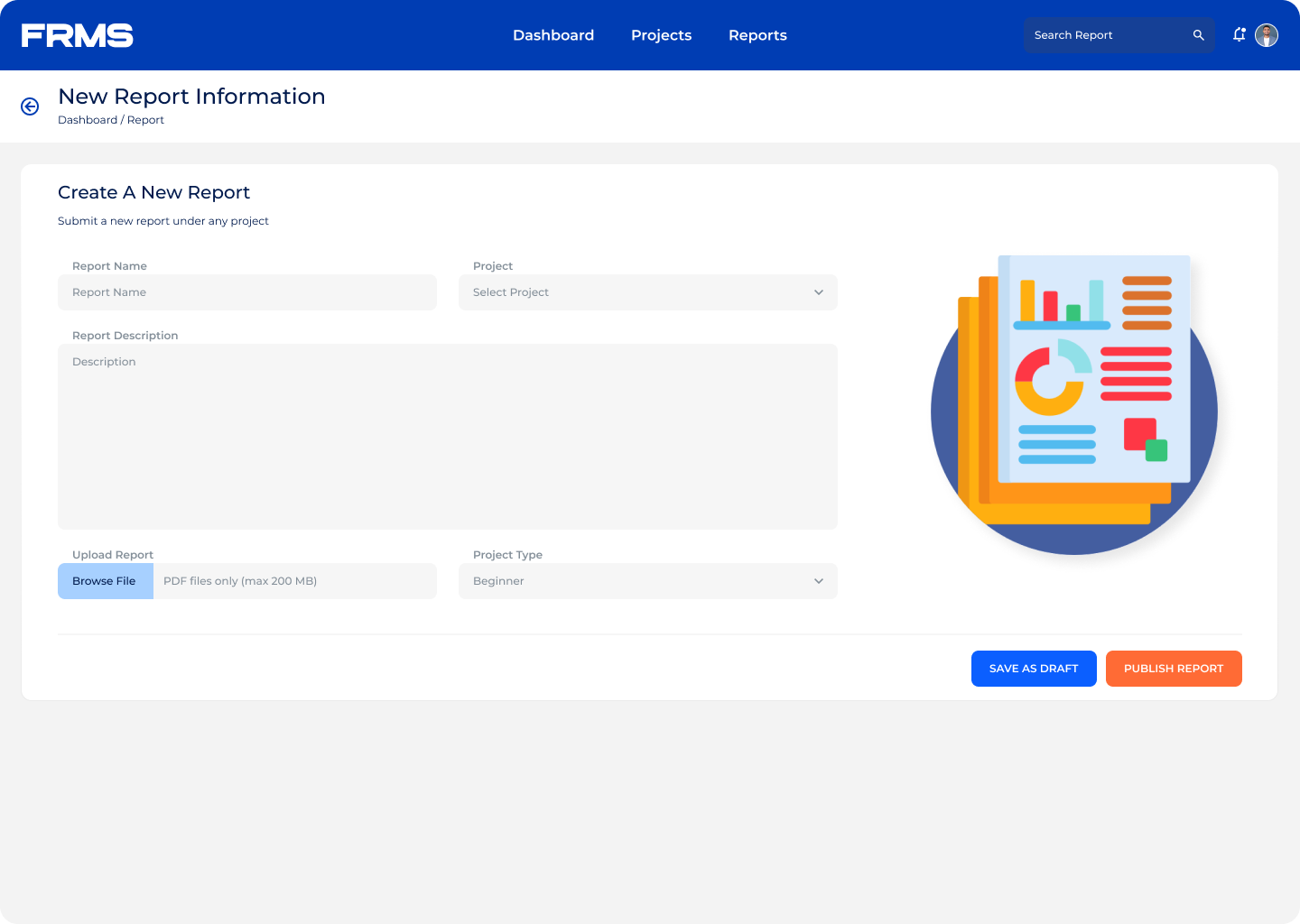
• Centralise research submission with a structured approval workflow
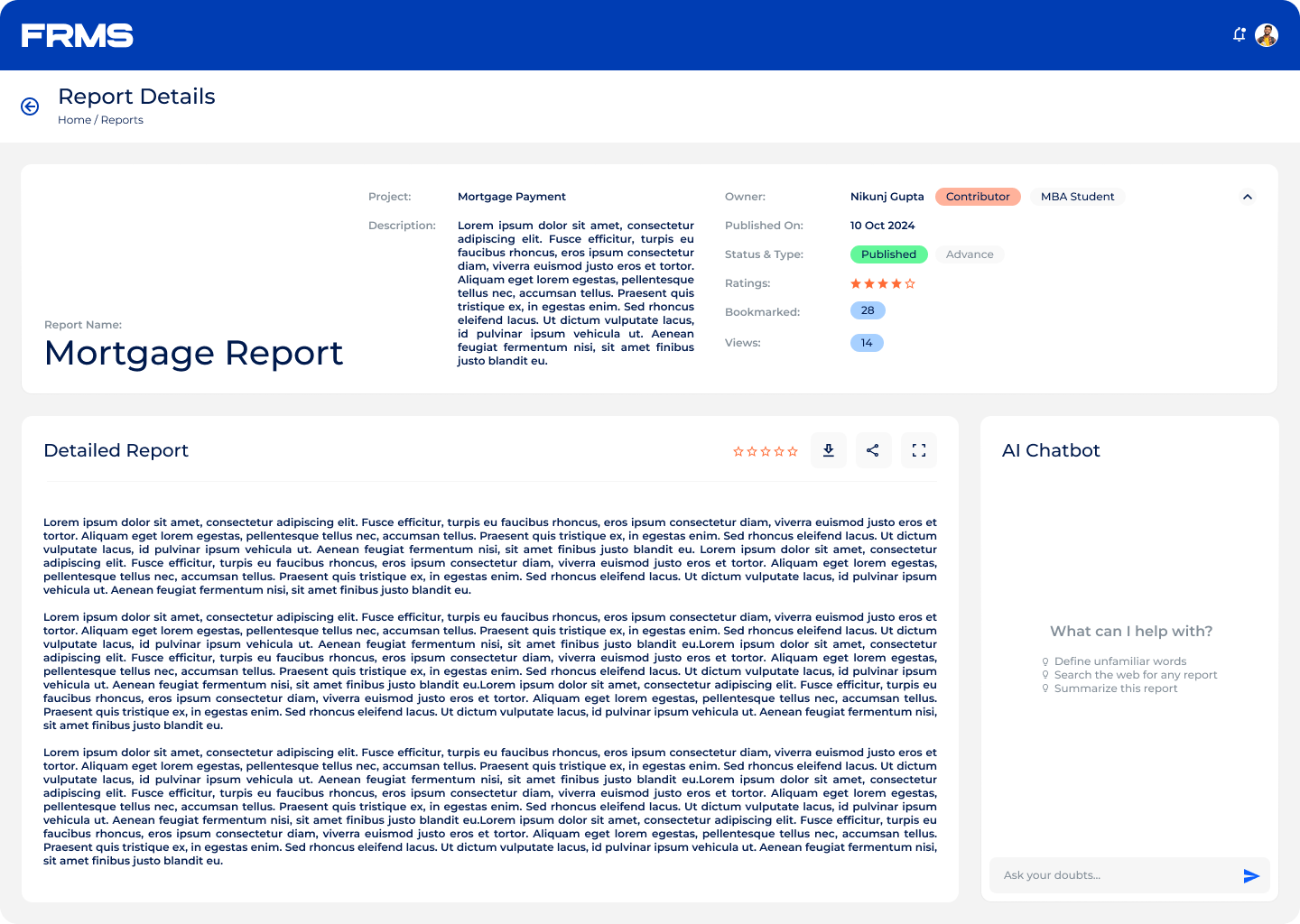
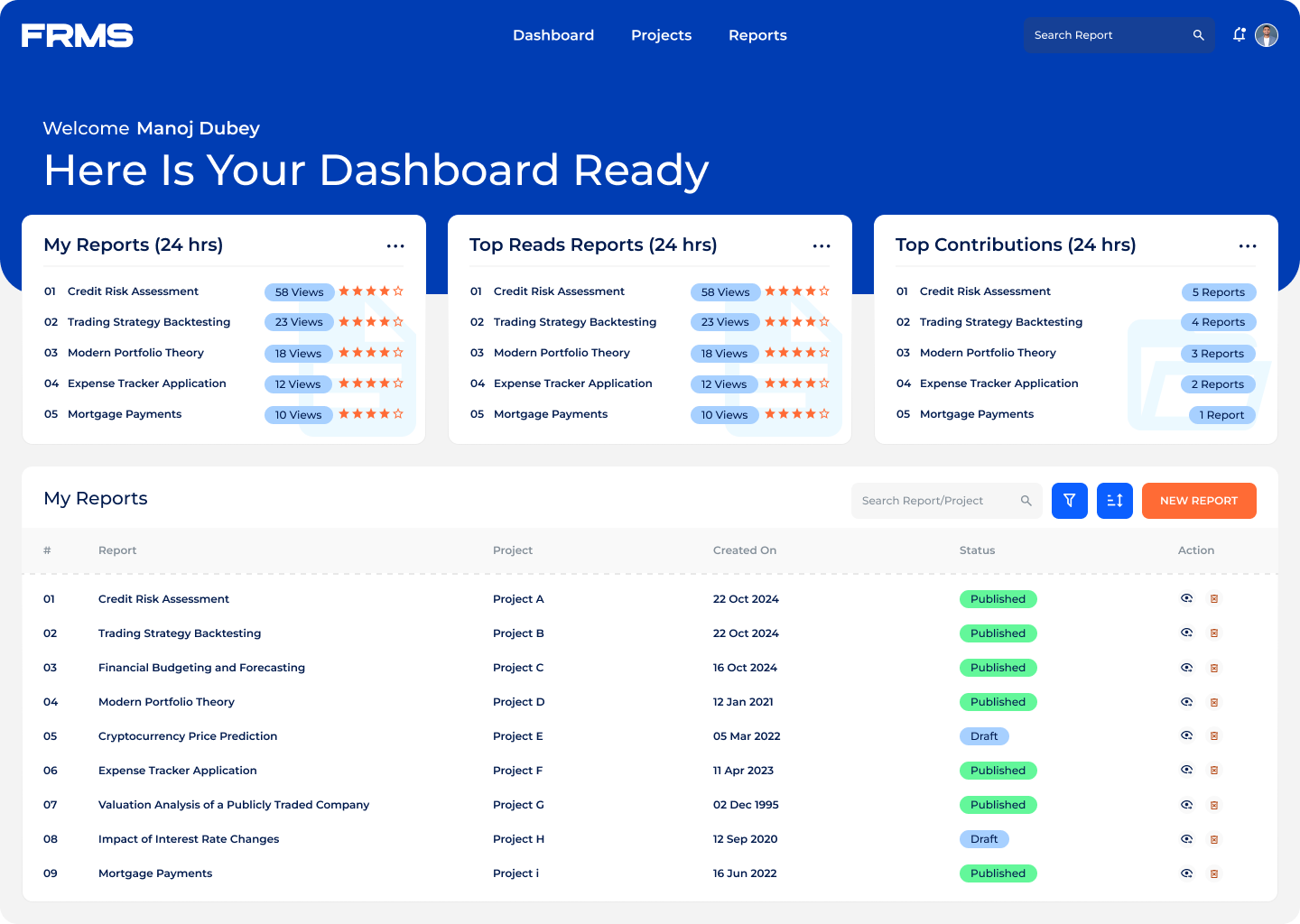
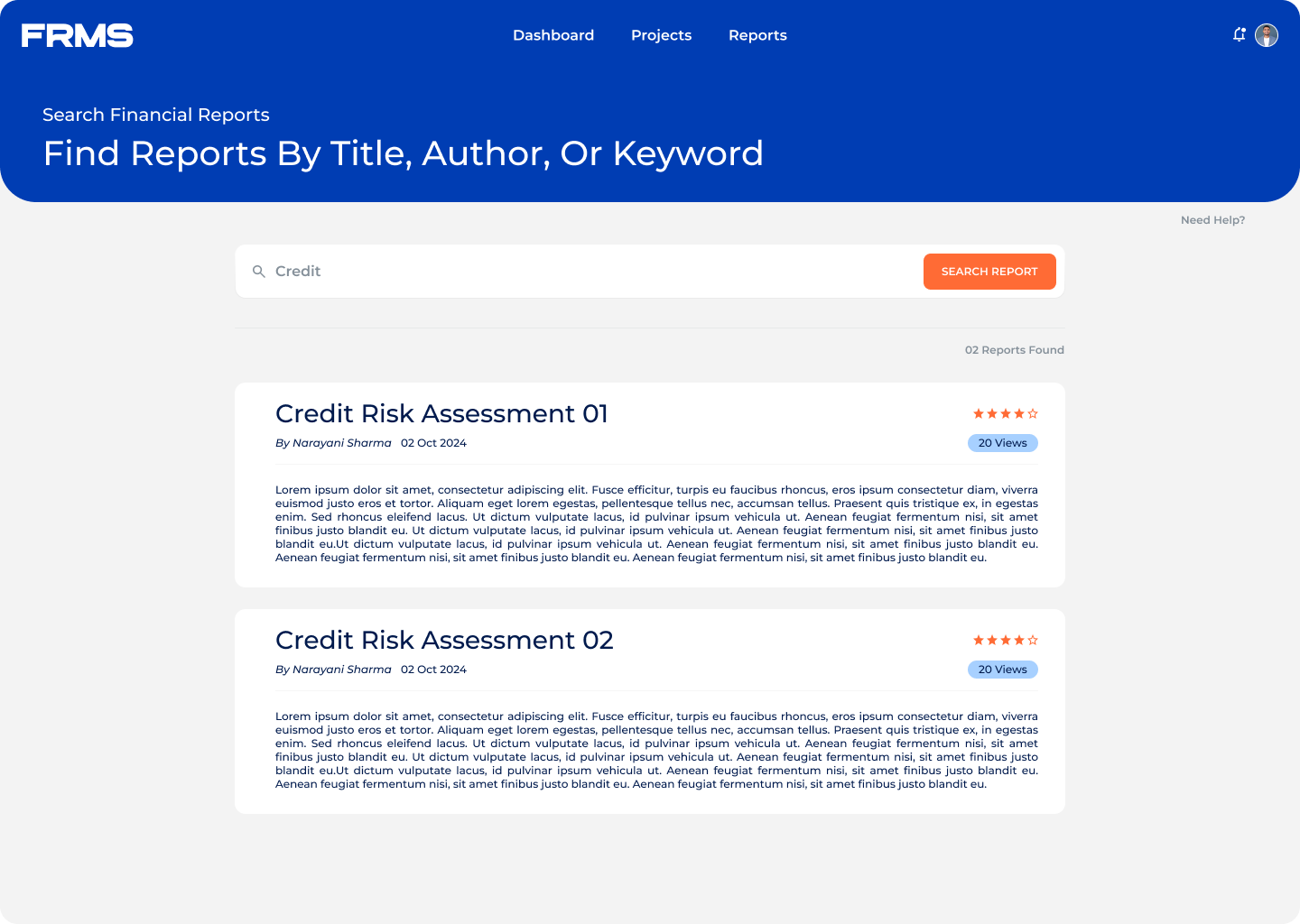
• Make research discoverable and accessible across the organisation
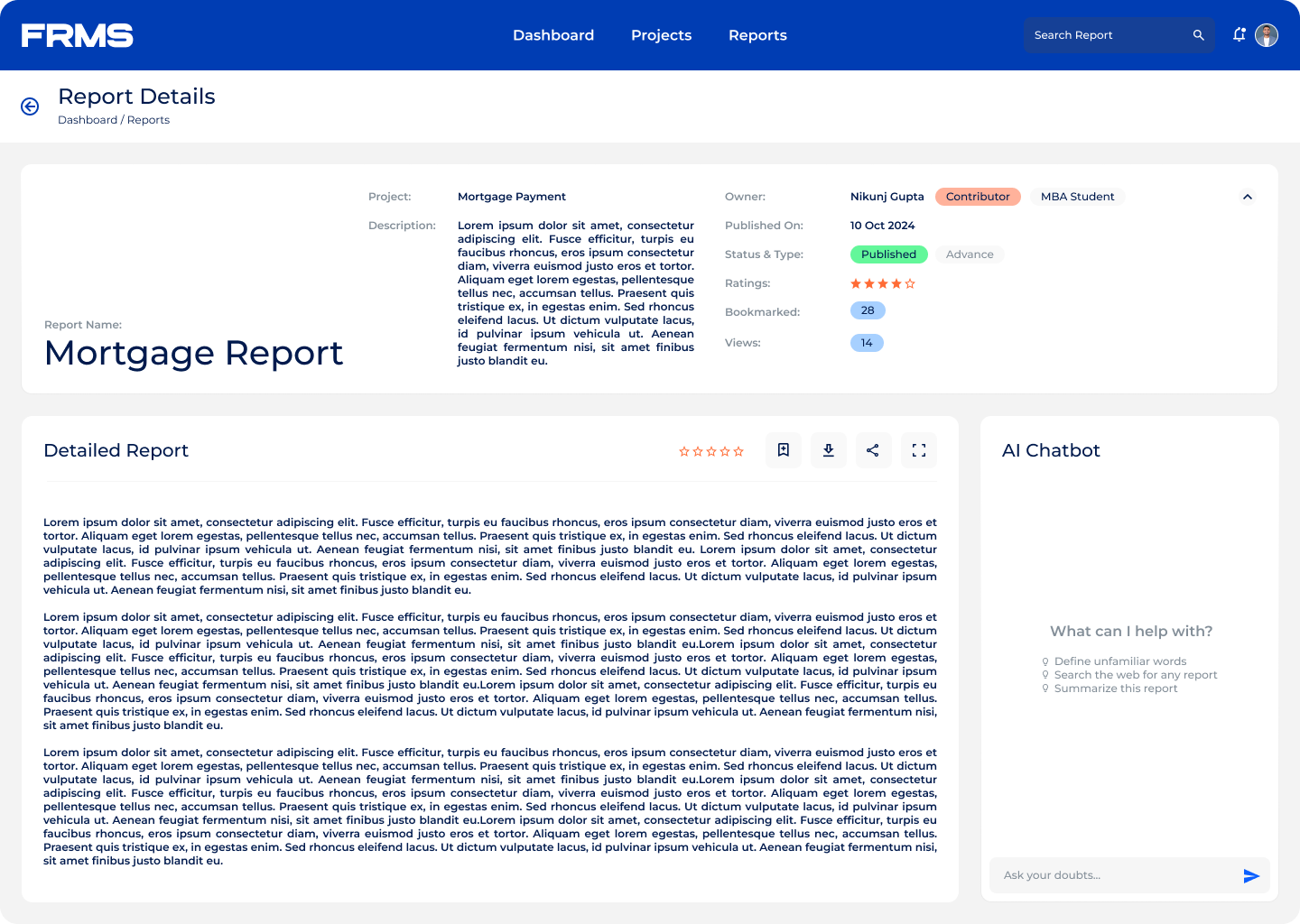
• Help readers understand complex financial terminology in context
• Give administrators visibility into research trends and engagement
• Maintain content quality through moderation